Yilin Wu 吴怡琳

PhD student @ RI, SCS, CMU
yilinwu [at] andrew [dot] cmu [dot] edu
Email is the best way to contact me!
I am a third-year Ph.D. student at Intent Lab in CMU Robotics Institute, advised by Prof. Andrea Bajcsy. I received my Master from Stanford CS, supervised by Prof. Dorsa Sadigh. In my undergrad, I was also fortunate to work with Prof. Lerrel Pinto and Prof. Pieter Abbeel.
For industry experiences, I have had great internships at Nvidia Seattle Robotics Lab and the Amazon Frontier AI & Robotics Lab.
My research interest lies in building better foundation models for robotics (fast, multi-modal world models) and leveraging those foundation models for inference-time adaptation (policy steering, etc.). I am also broadly interested in enhancing robots’ capabilities for more complex, long-horizon contact-rich manipulation with imitation learning, reinforcement learning, and multi-modal sensing.
Earlier at CMU, I was fortunate to work with Prof. David Held on generalizable methods for long-horizon contact-rich manipulation. During my Master at Stanford, I focused on assistive feeding and bimanual manipulation. I also worked with Prof. Yi Wu from Tsinghua University at Shanghai Qi Zhi Institute on reinforcement learning and self-imitation, and in my undergrad worked on reinforcement learning for deformable object manipulation.
More broadly, my research centers around overcoming the fundamental embodiment gap that limits the application of foundation models to robotics. By grounding high-level semantic reasoning in the continuous dynamics of the physical world, I want to build robots that can learn, reason, and act capably in human-centered environments, enhancing their generalization and robustness through runtime alignment and continual learning.
News
| Jul 2026 | Excited to give a talk at CMU RCHI Lab on how to build scalable inference-time policy steering with world modeling! |
|---|---|
| Jul 2026 | Excited to give a talk at UC Berkeley ICON Lab on how to build scalable inference-time policy steering with world modeling and verification! |
| Jun 2026 | SEAL received the Best Paper Award at the CVPR MMRAGI Workshop (Multi-modal Reasoning for Agentic Intelligence)! |
| Jun 2026 | Gave a spotlight talk about my recent two works UPS (Uncertainty-aware Policy Steering) and ViTaL (Inference-time Policy Steering via Vision and Touch) at CVPR 2026 H2R Workshop. |
| May 2026 | Started my summer internship at the Amazon Frontier AI & Robotics Team! |
| Apr 2026 | One paper Uncertainty-Aware Policy Steering (UPS) has been accepted at RSS 2026. |
| Jan 2026 | Excited to share my work from my internship at Nvidia (Do What You Say: Steering Vision-Language-Action Models via Runtime Reasoning-Action Alignment Verification) is accepted to ICRA 2026! |
| Nov 2025 | Excited to give a talk about my research on Language-Guided Runtime Steering with Robot Foundation Models at Duke DexLab (https://www.youtube.com/watch?v=sBBRs2N-qiw)! |
| Oct 2025 | Excited to give a talk about my research on Language-Guided Runtime Steering with Robot Foundation Models at UT Austin Robin Lab! |
| Jul 2025 | Excited to give a talk about my FOREWARN paper at Robotics Team in Meta FAIR ! |
| Jun 2025 | One paper From Foresight to Forethought: VLM-in-the-loop Policy Steering via Latent Alignment got accepted to RSS 2025. |
| May 2025 | Excited to start my summer internship in Nvidia Seattle Robotics Lab! |
| Jun 2024 | One paper Learning Generalizable Tool-use Skills through Trajectory Generation got accepted at IROS 2024. |
| May 2024 | Open X-Embodiment wins the Best Paper Award at ICRA 2024. |
| May 2024 | Two papers DROID and HACMan++ are accepted by RSS 2024. |
| Sep 2023 | Our work on bimanual manipulation inspired by human coordination is accepted to CoRL 2023 as Oral presentation. |
| Aug 2023 | Starting my Ph.D study at CMU Robitic Institute. |
Talks
| Jul 2026 | CMU RCHI Lab — Building Scalable Inference-Time Policy Steering with World Modeling |
|---|---|
| Jul 2026 | UC Berkeley ICON Lab — Building Scalable Inference-Time Policy Steering with World Modeling and Verification |
| Jun 2026 | CVPR 2026 H2R Workshop — Inference-Time Policy Steering via Uncertainty (UPS) and Vision-and-Touch (ViTaL) (Spotlight talk) |
| Nov 2025 | Duke DexLab — Language-Guided Runtime Steering with Robot Foundation Models [recording] |
| Oct 2025 | UT Austin Robin Lab — Language-Guided Runtime Steering with Robot Foundation Models |
| Jul 2025 | Meta FAIR Robotics Team — FOREWARN: VLM-in-the-loop Policy Steering via Latent Alignment |
Publications
- ICRA
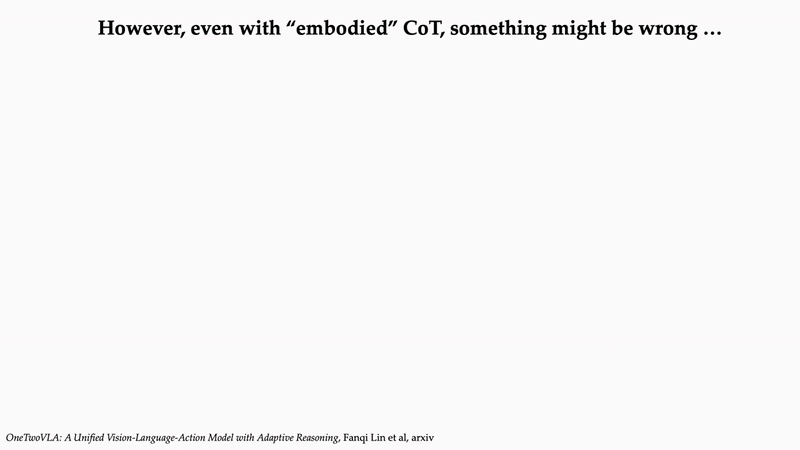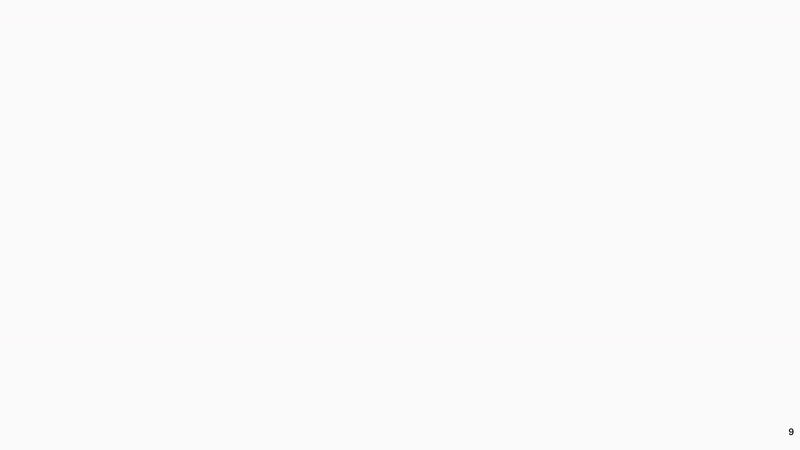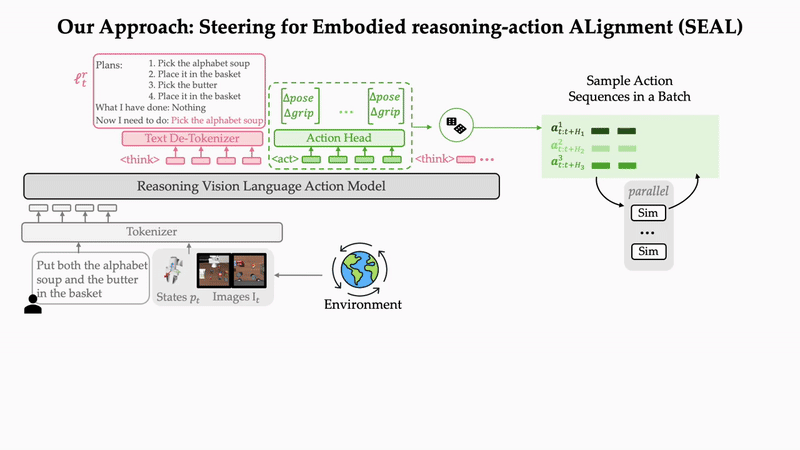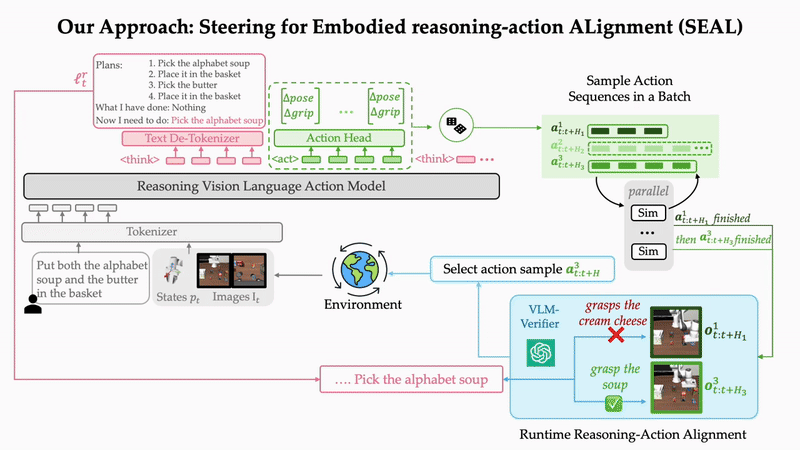 Do What You Say: Steering Vision-Language-Action Models via Runtime Reasoning-Action Alignment VerificationIn 2026 IEEE International Conference on Robotics and Automation (ICRA), 2026Outstanding Paper Award at CVPR 2026 2nd Multimodal Reasoning For Agentic Intelligence Workshop
Do What You Say: Steering Vision-Language-Action Models via Runtime Reasoning-Action Alignment VerificationIn 2026 IEEE International Conference on Robotics and Automation (ICRA), 2026Outstanding Paper Award at CVPR 2026 2nd Multimodal Reasoning For Agentic Intelligence Workshop















