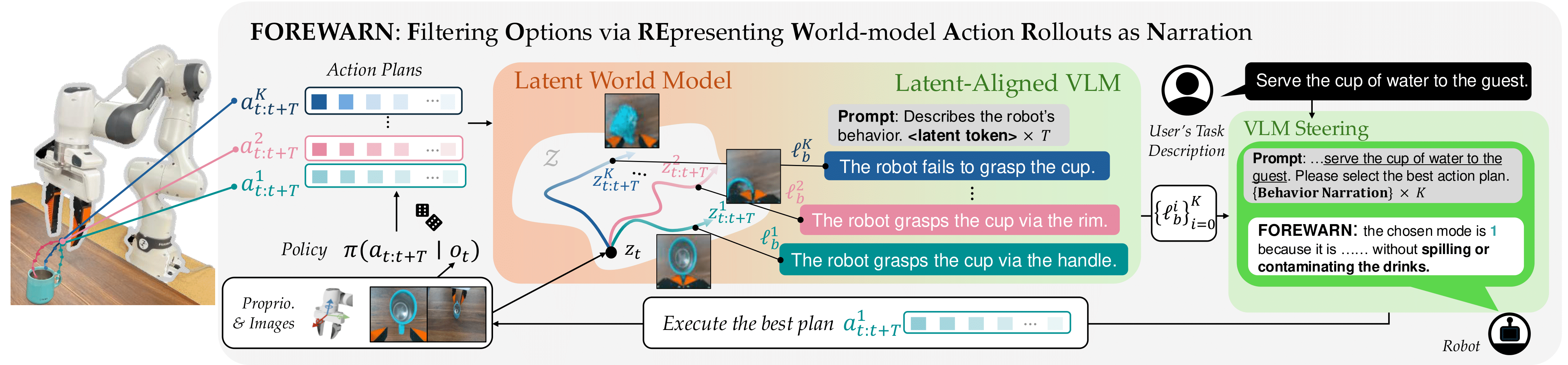
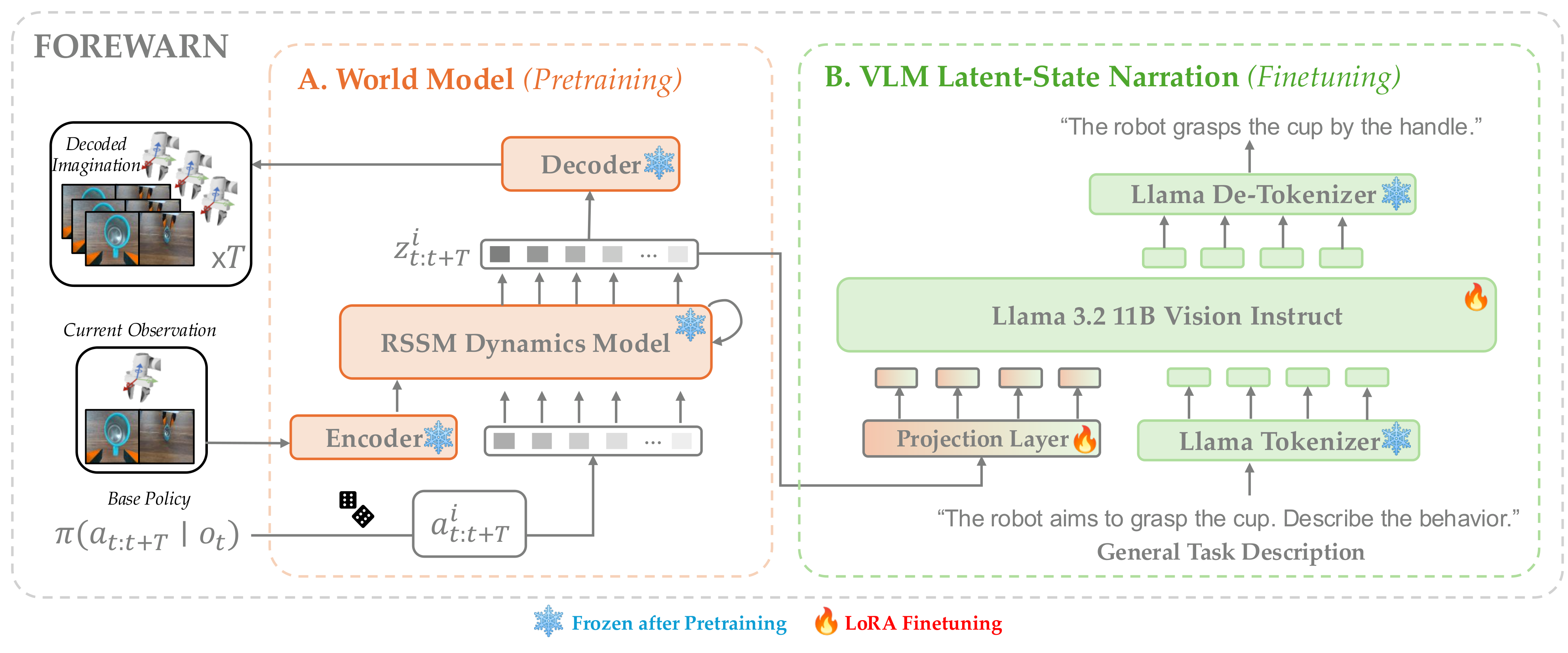
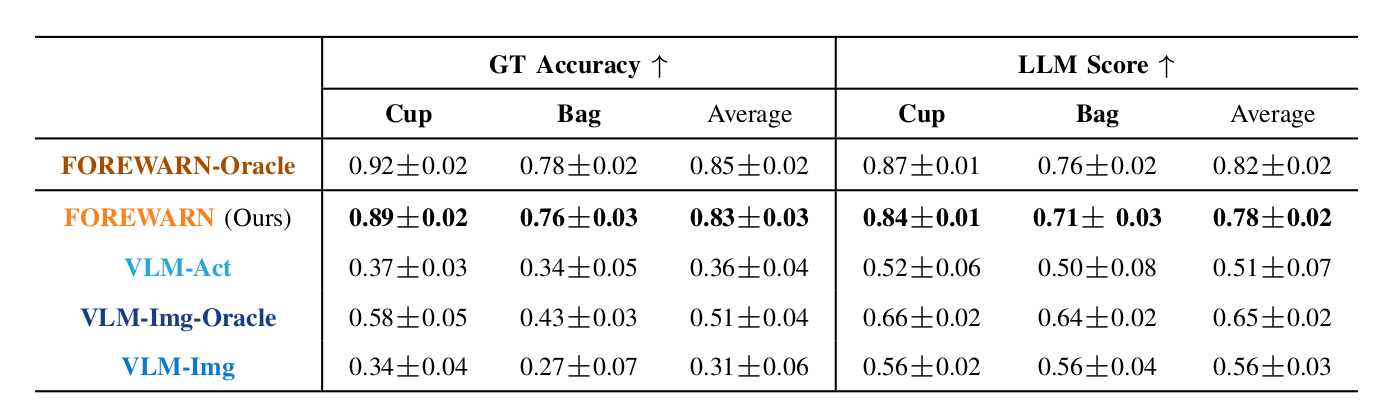
While generative robot policies have demonstrated significant potential in learning complex, multimodal behaviors from demonstrations, they still exhibit diverse failures at deployment-time. Policy steering offers an elegant solution to reducing the chance of failure by using an external verifier to select from low-level actions proposed by an imperfect generative policy. Here, one might hope to use a Vision Language Model (VLM) as a verifier, leveraging its open-world reasoning capabilities. However, off-the-shelf VLMs struggle to understand the consequences of low-level robot actions as they are represented fundamentally differently than the text and images the VLM was trained on. In response, we propose FOREWARN, a novel framework to unlock the potential of VLMs as open-vocabulary verifiers for runtime policy steering. Our key idea is to decouple the VLM’s burden of predicting action outcomes (foresight) from evaluation (forethought). For foresight, we leverage a latent world model to imagine future latent states given diverse low-level action plans. For forethought, we align the VLM with these predicted latent states to reason about the consequences of actions in its native representation—natural language—and effectively filter proposed plans. We validate our framework across diverse robotic manipulation tasks, demonstrating its ability to bridge representational gaps and provide robust, generalizable policy.